


Blog
Réussir les statistiques de sa thèse de médecine en 4 étapes : LE guide ultime 🚀

Réaliser l’analyse statistique de sa thèse peut sembler difficile voire inabordable. Pourtant, avec un peu d’organisation et quelques astuces, il te sera très facile de produire une thèse et un article scientifique de bonne qualité méthodologique. En lisant cet article, tu gagneras énormément de temps en évitant les erreurs qu’on a tous faites en préparant notre thèse de médecine ! Il y’a 4 grandes étapes lors de tout travail scientifique :
- Définir le sujet de la recherche et poser l’hypothèse
- Collecter les données
- Réaliser l’analyse statistique
- Rédiger le contenu du mémoire, de la thèse et/ou de l’article
Nous allons aborder ensemble ces différentes étapes pour éclaircir les problèmes que l’on rencontre tous au cours de la thèse de médecine, et te donner toutes les astuces des “pros” de la publication scientifique pour que ton travail de recherche aboutisse à une thèse puis à un article scientifique ! 💥
1. Définir le sujet de la recherche

Éviter les sujets pièges
Pour une thèse de médecine, il est fréquent que le sujet te soit “imposé” par ton directeur de thèse ou ton chef de service. Cependant, cela ne veut pas dire qu’il ne faut pas y réfléchir par toi-même. En effet, certains sujets sont des sujets “pièges” qui peuvent aboutir à une impasse et il faut être en mesure de réorienter l’hypothèse de recherche afin de respecter le temps qui t’est imparti et espérer publier ta thèse dans une revue scientifique.
Il existe plusieurs types de sujets piège pour une thèse :
- Les questions très générales qui manquent de spécificité : “Est-ce que le médicament ou l’intervention X est efficace ?”, “Quelle est la place de l’hypnose dans la prise en charge de la douleur ?”, … En effet, il est difficile de répondre à ces questions très vagues avec des moyens de recherche limités. Il faut plutôt s’intéresser à “l’efficacité du médicament ou de l’intervention X pour la pathologie Y dans la population Z”, ce qui est beaucoup plus abordable et te permettra de réaliser un travail avec une bonne rigueur méthodologique.
- L’étude d’une base de données existante mais qui contient beaucoup de données manquantes : il sera en effet très difficile de conclure à des choses intéressantes si le contenu est creux. Ou tu devras passer un temps extrêmement long à collecter les données ce qui est rarement compatible avec le temps nécessaire à la réalisation de ta thèse (et à faire des gardes en même temps …).
- Une question scientifique déjà largement étudiée et pour laquelle ton travail n'apportera pas de nouvel élément. Par exemple “Quel est l’intérêt de l’anti-agrégation plaquettaire dans la prise en charge des patients ayant eu un syndrome coronarien aigu ?”. Cette question a déjà été traitée par de nombreuses études randomisées de très bonne qualité méthodologique et il te sera difficile d’y apporter de nouveaux éléments à moins de disposer de très nombreuses données de qualité.
Si le sujet de recherche qui t’a été imposé fait partie de ces sujets pièges, il faut discuter avec ton directeur de thèse pour essayer de réorienter le travail vers une question plus accessible qui te garantira d’aller au bout de ton travail. Et pour cela, il n’y a pas d’autre choix que de réaliser une analyse précise et extensive de la littérature scientifique existante. Ceci te permettra de comprendre :
- Ce qu’ont fait les autres chercheurs avant toi
- Ce qui a déjà été prouvé plusieurs fois et ne nécessite pas de nouvelle recherche
- Les questions non encore résolues et qu’il serait intéressant d’approfondir
- Les critères d’inclusion et d’exclusion
- La taille approximative de l’échantillon qu’il te sera nécessaire d’étudier
- Les méthodes statistiques utilisées par les autres chercheurs pour répondre à une question similaire : comment étudier la performance d’un test diagnostique ? comment choisir les témoins dans une étude cas-témoin …
N’hésite surtout pas à en parler avec ton directeur de thèse ! Cela montrera que tu es impliqué dans ton travail de recherche, que tu as compris les tenants et aboutissants grâce à ton analyse de la littérature et surtout cela te permettra de produire un travail de meilleure qualité.
Poser la bonne hypothèse de recherche
C’est primordial pour produire une recherche intéressante et de bonne qualité méthodologique. Si ton hypothèse n’est pas bien réfléchie, tu ne seras pas en mesure d’y répondre statistiquement ! Il n’y a pas de recette miracle pour cela, mais certains points sont toujours vrais et peuvent te guider :
- Analyser de manière extensive la littérature scientifique existante : point de recherche sans connaissance ! Tu seras surpris de voir que nombre de tes idées ont déjà été étudiées ou au moins discutées par d’autres chercheurs. Connaître les travaux existants relatifs à ton travail de recherche te permettra de gagner énormément de temps et d’être plus pertinent.
- Choisir une hypothèse de recherche techniquement “faisable” : les grandes avancées en médecine ont souvent été faites par petites touches et il est difficile de résoudre d’un coup de baguette magique des grandes questions en suspens. “Comment guérir le VIH ?” ou “Quelle est la meilleure prothèse de hanche ?” sont rarement des sujets que tu verras traités car y répondre nécessite de découper le travail en plusieurs sous-questions.
- S’adapter aux ressources à ta disposition. Si ton travail porte sur une pathologie rare pour laquelle ton service n’a traité que quelques patients, il ne faut pas chercher à répondre à des questions trop précises. “Quels sont les facteurs prédictifs de la réponse au nouveau traitement non encore sur le marché chez 5 patients atteints de la maladie orpheline X porteurs de la mutation Y tout juste découverte ?”, ce ne sera pas possible. Rechercher des facteurs prédictifs nécessite plusieurs dizaines voire centaines de patients. Il sera alors plus intéressant de réaliser une analyse qualitative et précise de l’étude des 5 dossiers plutôt que de vouloir faire des statistiques à tout prix (parce que “ça fait bien une p-value” quand même 😉).
- S’adapter au temps à ta disposition. Si ta thèse est dans 6 mois et que tu n’as pas encore collecté les données, tout n’est pas perdu. Mais il va falloir éviter de choisir une hypothèse qui nécessite de grandes cohortes de patients.
Explorer les données à ta disposition
L’analyse de la littérature existante est cruciale. On ne le répétera jamais assez. Cependant, il est également intéressant de comprendre quelles sont les données dont tu disposes déjà. Si ton service est un centre expert d’une maladie rare, et que les données ont été bien collectées depuis 15 ans, tu disposes sans doute d’un grand avantage et pourras réaliser une étude très intéressante. De même si ton service utilise une même base de données, bien remplie depuis plusieurs années, tu auras sans doute intérêt à l’utiliser comme base de ton travail. Il ne faut pas non plus négliger les complications des pathologies ou des traitements qui sont souvent des sujets de recherche très intéressants. Si ton chef de service a l’habitude de prendre en charge toutes les complications post-opératoires des chirurgiens alentour, cela peut constituer un sujet de recherche passionnant.
Si après avoir lu tout ceci, tu ne sais toujours pas si ton sujet de recherche est le bon, il te reste 2 choses à faire :
- Analyser la littérature scientifique ! (L’enseignement c’est la répétition 😌)
- Discuter avec ton directeur de thèse et d’autres médecins qui connaissent le sujet
2. Collecter les données

Après un bon sujet de recherche, la collecte des données est le point le plus crucial pour réussir ton analyse statistique ! En effet, même la meilleure méthodologie statistique ne permet pas de compenser des données mal collectées. Heureusement, il existe de nombreuses astuces qui te permettront de travailler de manière efficace et donc plus rapide.
Ces astuces peuvent se résumer en 3 points :
- Collecter les données appropriées à ton hypothèse de recherche
- Collecter les données de manière structurée (ou comment devenir le roi du tableau Excel)
- Numériser un maximum de données non structurées pour pouvoir accéder rapidement à des informations auxquelles tu n’avais pas pensé lors de ta collecte de données
Collecter des données appropriées à l’hypothèse de recherche
D’une manière générale, il faut prendre en compte les études déjà publiées sur des sujets de recherche similaires :
- Collecter des indicateurs et scores déjà utilisés dans la littérature pour que ton étude puisse être comparée à d’autres études similaires (on avait déjà parlé de l’importance de l’analyse de la littérature existante ?)
- Collecter les facteurs de confusion potentiels pouvant intervenir dans la réponse au traitement. Étudier l’efficacité d’une chimiothérapie n’a pas de sens si l’on ne connaît pas le stade de dissémination du cancer. Analyser les facteurs de risque de récidive de l’instabilité d’épaule nécessite de savoir si les patients étaient épileptiques ou non …
Et plus spécifiquement :
- Si tu veux étudier l’efficacité d’un traitement pour une maladie donnée, il faut généralement collecter des données pré-traitement et post-traitement pour pouvoir faire une comparaison avant/après.
- Si tu veux étudier des facteurs de risque d’une pathologie ou d’une complication, il faudra un nombre important de patients ou de témoins, notamment si la pathologie est rare.
- Si tu veux étudier un nouveau signe clinique ou une nouvelle classification, il faudra généralement réaliser une analyse inter-observateurs et intra-observateurs et donc demander la participation de tes collègues et/ou de tes chefs.
Structurer les données
Maintenant que tu as une hypothèse de recherche solide et que tu connais les données que tu vas recueillir, il faut créer ton tableau de recueil de manière intelligente. Il existe plusieurs façons de faire qui dépendent des habitudes de chacun mais voici une méthode simple et efficace pour recueillir les données de ta thèse de médecine :
- Rédige un formulaire “papier” : avant de te jeter sur ton tableau Excel, il vaut mieux utiliser Word ou une bonne vieille feuille de papier et un stylo. En effet, même si les logiciels sont forts pour traiter des données de tableur qui sont disposées horizontalement, il est plus facile pour nous - simples humains - de réfléchir de manière verticale aux problèmes.
- Pars du généraliste vers le spécifique. En recherche clinique, on a toujours besoin de l’âge et du sexe des patients, de leur durée de suivi, de leur date d’inclusion, de la date des dernières nouvelles et de la date de décès éventuellement. On a également souvent besoin de connaître les comorbidités des patients. Inutile de lister toutes les pathologies existantes, il vaut mieux se concentrer sur ce qui a un rapport avec ton sujet de recherche. Ensuite, il faut s’intéresser à ta problématique de recherche. Si tu étudies un traitement chirurgical, il faut collecter les données du compte-rendu opératoire pour pouvoir plus tard analyser les résultats en fonction des choix du chirurgien. Enfin, il faut recueillir les résultats cliniques ou paracliniques à proprement parler, en n’oubliant pas les données pré-traitement si tu étudies l’efficacité d’un traitement.
- Privilégie les questions fermées aux questions ouvertes. Par exemple, si tu recueilles les comorbidités d’un patient, il vaut mieux créer 5-6 colonnes avec des réponses binaires de type oui/non, plutôt que de créer une colonne de texte libre qui ne sera pas analysable statistiquement. D’une manière générale, les variables oui/non sont plus facilement analysables statistiquement que les autres variables car elles permettent de diviser ta population en deux (les “oui” et les “non”) et donc d’obtenir généralement une meilleure puissance statistique.
- Découpe les données en plusieurs colonnes. Par exemple, si tu as une colonne “complication” et que tu y notes des informations comme “Oui, rash cutané allergique à J2 post-traitement”, il vaut mieux créer 4 colonnes distinctes : “Complication (oui/non)”, “Type de complication” (allergique, intolérance, complication majeure), “Délai d’apparition en jours” (valeur numérique) et “Détails des complications” où tu pourras écrire des commentaires qui ne seront pas analysés statistiquement.
- Ne mets pas de commentaires à côté des valeurs ! On voit fréquemment dans des tableaux de recueil de thésards des valeurs comme “Oui (mais que la nuit)”. Hors, cette mauvaise habitude va tout simplement ruiner ton analyse statistique car ta question attend “oui” ou “non” comme réponse, et les ordinateurs ne comprennent pas les commentaires, pourtant si importants pour les chercheurs. Puisque ces commentaires sont tout de même importants, il est préférable de les collecter dans une colonne séparée qui ne sera pas analysée statistiquement.
- Tu peux utiliser un e-CRF, c'est-à-dire une application spécifiquement dédiée à la collecte de données de patients qui permet de générer une base de données propres en structurant automatiquement les données. EasyMedStat dispose par exemple d’un e-CRF intégré (mais tu peux également importer un tableau Excel si tu l’as déjà constitué).
Conserver un maximum de documents
Comme tu seras content de l’avoir fait, lorsque 2 semaines avant ta thèse, ton directeur de thèse ou ton chef de service te demandera “Et au fait, as-tu étudié l’influence de ce facteur ?” et que tu te rendras compte que tu n’as justement pas collecté ce facteur dans ton tableur 🙀 ! En effet, même si tu es un As de la recherche, il est rarement possible d’anticiper toutes les questions que tu vas te poser ou que l’on va te poser. Et il faudra souvent retourner dans les dossiers des patients pour collecter de nouvelles données. Si toutes les données de tes patients sont dans des dossiers papiers, cette tâche risque d’être extrêmement fastidieuse, voire impossible. Alors que si tu as conservé une copie numérique pseudonymisée du dossier papier, il te sera bien plus rapide de retrouver les informations manquantes.
Veille bien à respecter les réglementations RGPD et de la CNIL pour ne pas risquer que les données personnelles des patients soient exposées. Si tu stockes les données sur ton ordinateur personnel, il faudra les supprimer après la fin de ta recherche. Dans tous les cas, il est nécessaire d’obtenir le consentement des patients si ta recherche est interventionnelle (se renseigner sur la Loi Jardé...).
3. Réaliser l'analyse statistique
“C’est là que les Athéniens s’atteignirent” comme dit le proverbe. Mais ne t’en fais pas, des solutions existent pour réaliser ton analyse statistique.
Tout d’abord si tu as bien suivi nos conseils précédents sur le choix du sujet de recherche et la collecte des données, ton analyse statistique sera grandement facilitée. Ensuite, il existe de nombreuses méthodes pour faire ses statistiques. La meilleure solution dépend généralement de la question que tu dois traiter. D’une manière générale, il vaut mieux réaliser soi-même les statistiques afin de comprendre en profondeur tes résultats. Cela n’empêche pas de les faire valider ensuite par un expert en statistiques. Il te sera d’ailleurs plus facile de trouver quelqu’un qui veuille relire tes résultats plutôt que de faire toute l’analyse statistique à ta place !
Quels outils pour faire mon analyse statistique ?
Si tu as la chance d’avoir une étude financée par un PHRC (programme hospitalier de recherche clinique) et d’avoir impliqué la DRCI (direction de la recherche clinique et de l’innovation) dès le début de ta recherche, tu pourras probablement demander leur aide pour l’analyse statistique. Cependant, ce genre de projets est assez rare pour une thèse de doctorat en médecine car il faut plusieurs années pour les mener à bien.
Si tu es dans le cas de l’immense majorité des internes qui n’ont pas fait appel à la DRCI pour mener ta recherche, tu devras te débrouiller et trouver une autre solution. Il existe alors 3 situations :
- Tu es un expert en statistiques et tu sais coder ou utiliser des logiciels de statistiques, alors tu vas sûrement utiliser R, SPSS ou Graphpad. Attention, ces logiciels sont très puissants mais nécessitent d’avoir de bonnes connaissances en statistique et ne devraient pas être utilisés par des novices ! Le risque est d’utiliser des méthodes inappropriées, de conclure à tort et de voir tes espoirs de publication réduits à néant car les reviewers ne laisseront pas passer des erreurs méthodologiques.
- Ton meilleur ami ou ton compagnon est un expert en statistiques … Petit veinard.
- Tu n’as que très peu voire aucune connaissance en statistiques. Rassure-toi c’est le cas de la majorité des internes en médecine qui préparent leur thèse.
Si tu es dans ce dernier cas, réaliser soi-même ses statistiques reste tout de même une bonne pratique. Cela te permettra de mieux comprendre tes résultats, et de répondre au fur et à mesure aux nouvelles questions que tu vas te poser. Cependant, il te faut des outils appropriés pour ne pas faire d’erreur.
Il existe des calculateurs en ligne tels que Biostatgv ou Medcalc, qui peuvent être bien pratiques lorsque l’on sait exactement le test que l’on doit faire et qu’on n’a que très peu d’analyses statistiques. Cependant, cela ne convient pas à un travail de recherche complet comme celui d’une thèse de médecine.
Un outil adapté aux thèses de médecine existe. EasyMedStat est une application en ligne de statistiques développée par un médecin qui permet justement de réaliser ses analyses statistiques sans avoir de connaissances en stats ! Le principe est simple : tu poses une question clinique, par exemple, quel est le lien entre “ ge du patient” et “Risque de complications” et l’application choisit pour toi le bon test statistique ! Pas besoin de choisir entre un Chi-2, un Student ou un Kruskal-Wallis puisque le choix est fait pour toi, en fonction de ta question et des données à ta disposition. Ainsi, tu ne risques pas de te tromper. Tu peux également réaliser des analyses de survie et des analyses multivariées sans avoir à coder quoi que ce soit.
Faire une analyse statistique du plus général vers le plus particulier
Quand on a réussi à faire son analyse statistique, on en est très fiers. Et on a envie de “montrer ses p-values” !! Mais c’est une erreur de penser que ce sont les résultats les plus importants ! En effet, beaucoup de thésards oublient de parler des choses les plus simples avant de présenter les résultats des analyses statistiques poussées. Par exemple, avant de chercher les facteurs de risque de mortalité d’une population, il faut d’abord étudier la mortalité elle-même. C’est-à-dire, donner le simple nombre de patients décédés dans la population, le pourcentage que cela représente et fournir les courbes de survie.
Voici un plan d’analyse assez classique pour une étude rétrospective :
- Description de la population : combien de patients, quel âge moyen, % d’hommes et de femmes, durée moyenne de suivi, antécédents médicaux, éventuellement comparabilité des groupes si la population est divisée en sous-groupes …
- Description des interventions : combien de patients dans chaque groupe de traitement, détails des traitements reçus
- Description des complications : % de complication, courbes de survie, détails des complications
- Résultats cliniques et paracliniques avec différence avant/après traitement si l’étude est appropriée
- Études en sous-groupes
- Facteurs de risque de complications, de mauvais résultats, … (voir analyse multivariée)
Nettoyer ses données
Avant de commencer quelque analyse que ce soit, il faut vérifier qu’on n’a pas de valeurs aberrantes en regardant les minimum et maximum de chacune des variables. Il arrive parfois qu’on saisisse qu’un patient mesure 170 mètres parce qu’on pensait à tort que la taille était notée en centimètres dans le tableur ! Il faut corriger ces erreurs avant de faire l’analyse statistique. Autrement, tu risques de devoir tout recommencer plusieurs fois en te rendant compte au fur et à mesure des erreurs rencontrées.
Utiliser un bon sens critique
L’autre avantage de réaliser soi-même les statistiques de son étude est qu’on peut avoir un œil critique sur les résultats et ajuster rapidement. Lorsque tu produis un résultat statistique incroyable, avant de penser au prix Nobel de médecine, essaye de vérifier les points suivants :
- Y’a-t’il un problème dans les données ? Ai-je des valeurs aberrantes, des données fausses ? Dans la majorité des cas, c’est la raison de ce résultat extraordinaire.
- Y’a-t’il un facteur de confusion ? Il est possible qu’un facteur “invisible” intervienne dans les résultats et fausse tes conclusions. Par exemple, la durée de vie des femmes est généralement plus longue que celle des hommes, donc si tu trouves un résultat inverse, il faut regarder si les femmes de ton échantillon de patients ne souffrent pas plus fréquemment de certaines pathologies qui pourraient expliquer ce résultat.
4. Rédiger le manuscrit
Il ne faut pas se précipiter pour rédiger le manuscrit mais il ne faut pas non plus attendre la dernière minute. Il faut prévoir un mois pour la rédaction et la correction du manuscrit si tu as bien respecté toutes les étapes précédentes et que tu suis nos conseils. L’objet ici n’est pas de te décrire en détail la méthode de rédaction d’un article médical mais plutôt de te donner quelques conseils pratiques pour optimiser ta rédaction.
Pour rédiger un manuscrit de thèse de manière efficace, voici nos conseils :
- Commence par faire une présentation (Powerpoint) avant de rédiger le manuscrit
- Ne te contente pas de donner les p-values
- Présente les résultats avec des graphiques et des tableaux
- Fais relire ton manuscrit par un autre médecin non expert du sujet
Résumer son manuscrit dans une présentation Powerpoint
Cela peut paraître étonnant mais il vaut mieux commencer par faire une présentation Powerpoint plutôt que de rédiger un manuscrit. Commencer par un Powerpoint avant son manuscrit de thèse présente plusieurs avantages :
- C’est plus rapide à concevoir : écrire un manuscrit est très long alors que faire une présentation ne te prendra que quelques heures.
- C’est plus digeste pour ton directeur de thèse et tes correcteurs : corriger la première version d’un manuscrit de thèse est une tâche très fastidieuse. Plus tu simplifieras la vie de ton directeur de thèse, plus vite il te fera ses retours et tu pourras ainsi gagner du temps.
- Cela permet de synthétiser ses idées. Une des principales erreurs que font les thésards est de rédiger des manuscrits à rallonge. C’est normal, tu as tellement travaillé ton sujet que tu en es devenu un expert et tu penses que chaque détail est important. Cependant, la plupart des gens qui vont lire ta thèse puis ton article ne sont pas des experts et si tu les noies dans des détails, ils n’arriveront pas à extraire la substance de tes résultats.
- Cela permet de voir rapidement s’il existe des problèmes méthodologiques majeurs dans ton étude ou des résultats manquants. Et plus vite tu t’apercevras de ces problèmes, plus vite tu pourras les résoudre. Il vaut mieux ne pas attendre la dernière minute pour se rendre compte que tu as oublié de collecter une donnée très importante.
- C’est du temps gagné sur ta présentation de thèse. En effet, tu seras tout de même obligé de faire un Powerpoint pour présenter ta thèse au final, donc ce temps ne sera pas perdu.
- Cela te permet de t’entraîner à l’exercice oral de présentation de ta thèse.
Ne pas souffrir du syndrome de la p-value
Qu’on est fiers d’avoir calculé les p-values et trouvé des différences ou des associations statistiquement “significatives” ! Mais la p-value ne donne finalement que très peu d’informations à tes lecteurs. Il est fréquent de voir des phrases telles que “Les patients ayant reçu le traitement A avaient une douleur inférieure à ceux ayant reçu le traitement B (p=0.002)”. Hors, ceci ne nous dit pas quelle est l’importance de l’effet. On peut en effet avoir une p-value très basse avec une différence minime entre les deux groupes si l’échantillon est suffisamment grand. Il faut toujours préciser la magnitude de l’effet et son intervalle de confiance à 95%. Par exemple, il faudrait dire : “Les patients ayant reçu le traitement A avaient une douleur inférieure à ceux ayant reçu le traitement B (différence moyenne : -3,5/10, IC95 = [-4,7 ; -2,3], p=0.002).”. Ainsi, on se rend compte qu’il y’a une différence de 3,5 points sur 10 et que dans 95% des cas, cette différence serait d’au moins 2,3. L’effet du traitement est donc cliniquement significatif.
Présenter ses résultats avec des graphiques et des tableaux
Les chiffres c’est bien mais les graphiques c’est plus parlant. Il est toujours intéressant de présenter ses résultats les plus importants sous un format visuel à l’aide de graphiques. C’est notamment le cas lorsque tu présentes :
- Des résultats de comparaison de groupes : boites à moustaches
- Des analyses de survie : courbes de Kaplan-Meier
- La distribution d’une variable numérique : histogramme
En utilisant EasyMedStat, les graphiques sont générés automatiquement en fonction des données.
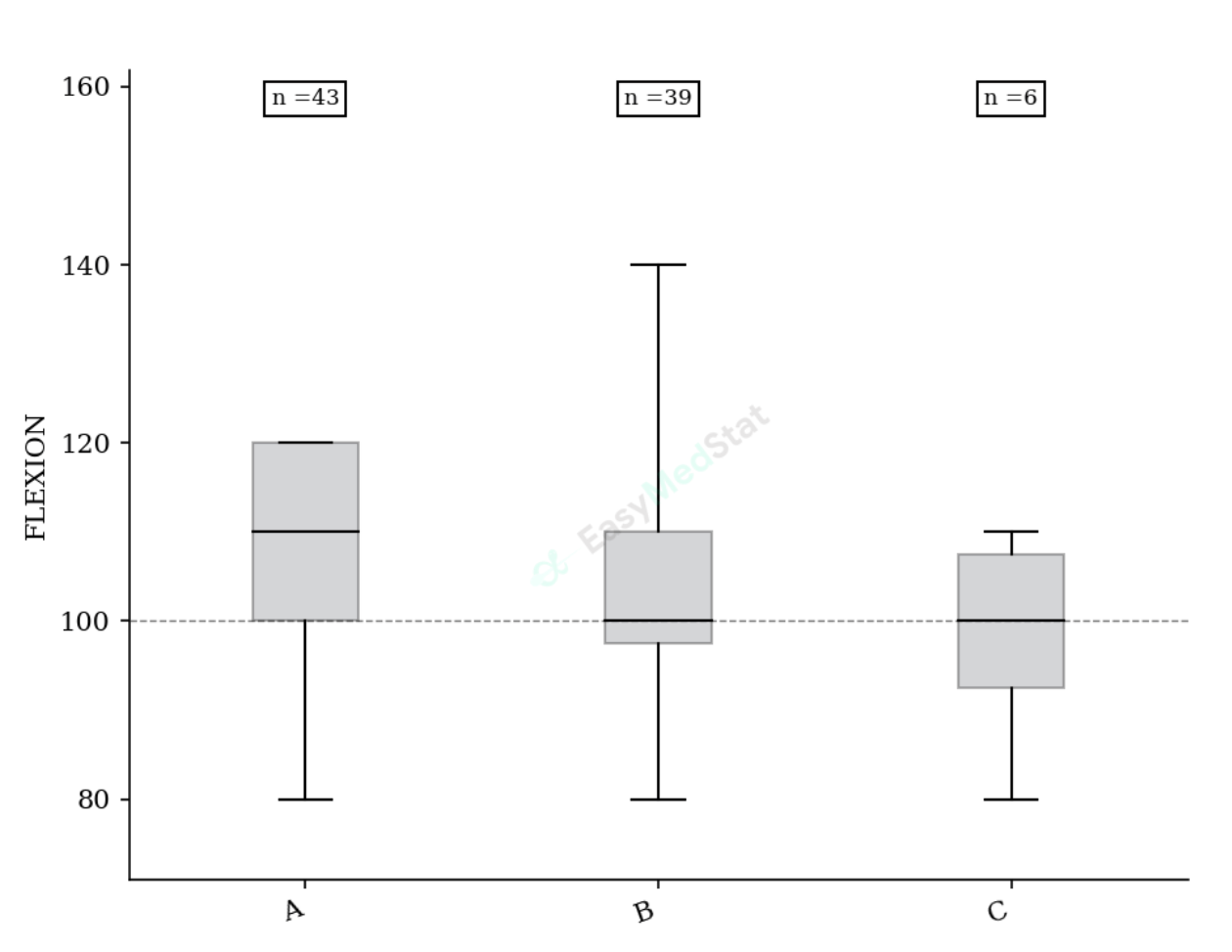
Les tableaux sont également souvent indispensables pour permettre de limiter le nombre de résultats numériques affichés dans le texte. Il n’est en effet pas nécessaire de présenter tous tes résultats numériques dans le manuscrit. Cela peut même devenir indigeste. Il faut limiter le nombre de résultats affichés, et dans le manuscrit privilégier les résultats principaux. Il est par exemple fréquent de présenter les tableaux suivants :
- Caractéristiques démographiques de la population
- Comparabilité des groupes
- Comparaison des résultats entre deux groupes
Faire relire ton manuscrit par un médecin non expert du sujet
L’intérêt d’écrire un manuscrit puis un article est avant tout de communiquer tes résultats auprès de tes pairs. Il est donc primordial que ton manuscrit soit facile et agréable à lire. Un bon exercice pour vérifier la lisibilité de ta thèse est de la faire relire par un médecin d’une autre spécialité. Il ou elle aura les connaissances nécessaires pour comprendre la méthodologie mais n’aura pas l’expertise sur le sujet même de ta thèse et c’est là tout l’intérêt. Si tu es capable de transmettre à un non-expert le contenu de ta recherche, alors tous les lecteurs (et donc ton jury de thèse puis les reviewers des journaux) prendront goût à lire l’article.
En conclusion
Réussir les statistiques de sa thèse de médecine, ça ne veut pas dire être un génie des mathématiques. Il ne faut jamais se jeter à corps perdu dans l’analyse statistique avant d’avoir respecté certaines étapes. C’est avant tout une question de méthodologie :
- Analyser encore et encore la littérature scientifique existante
- Poser la bonne question de recherche
- Collecter des données de manière structurée
- Conserver une copie (de préférence numérique) des données qui ne rentrent pas dans un tableur Excel
- Utiliser des outils statistiques simples comme EasyMedStat
- Garder en tête que ton travail devra surement être publié dans une revue scientifique à comité de lecture après ta thèse
Si tu veux en savoir plus sur le sujet, inscris-toi à notre newsletter pour être informé des prochains webinaires “1 heure pour ta thèse” que nous organisons.
LATEST POSTS
Risques compétitifs : méthodes d’Aalen-Johansen et test de Gray désormais intégrées dans EasyMedStat



Let your friends know!